

Este documento, estructurado en tres partes, tiene como objetivo dar una visión con cierto nivel de detalle de lo que es el Big Data Analytics y la inteligencia Artificial, así como justificar su necesaria y urgente aplicación en el sector de la Construcción.
En este primer artículo se procederá a realizar las definiciones necesarias dentro de un relato histórico de las tecnologías y disciplinas matemáticas de base incorporadas para su mejor entendimiento.
En la segunda entrega se presentará la evolución de las tecnologías de bases de datos, desde las bases de datos relacionales hasta la irrupción del Big Data y las tecnologías analíticas incorporadas a comienzos de la presente década.
Y en la tercera entrega se abordará el estado actual de adopción de Big Data Analytics y las tecnologías de Inteligencia Artificial en la industria de la Construcción, así como el potencial y aplicaciones que presentan estas tecnologías en varios subsectores de dicha industria.
1. Antecedentes
La Industria de la Construcción es uno de los pilares relevantes por su impacto en el bienestar económico y social de los países. En la Unión Europea, el sector es un pilar estratégico para su bienestar económico y social. En 2017, supuso casi el 9 % del producto interior bruto (PIB) de la UE, generó 14,5 millones de puestos de trabajo directos (el 6,4% del empleo total de la UE) repartidos en 3,1 millones de empresas y un efecto inducido de 29,1 millones de empleos indirectos, y repercute directamente en la seguridad de las personas y en su calidad de vida[1].
Uno de los principales y persistentes problemas de esta industria, es la productividad (figura 1). Desde hace más de 20 años, ha crecido muy poco –un 1%-, mientras que la economía mundial lo ha hecho a un ritmo del 2,8% y la industria manufacturera, al 3,6%. Si el Sector de la Construcción hubiese alcanzado en términos de productividad la misma tasa de crecimiento que la registrada por la economía mundial, podría generar un valor añadido anual de 1,6 billones de dólares, que es la mitad de las necesidades anuales de inversión en infraestructuras de todo el mundo.
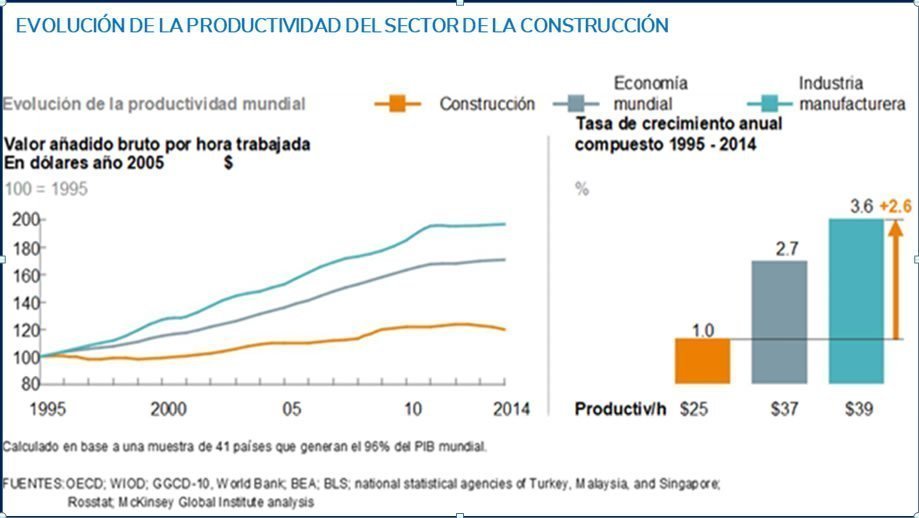 Figura 1: Evolución de la productividad del Sector de la Construcción
Figura 1: Evolución de la productividad del Sector de la Construcción
En uno de sus análisis, la prestigiosa consultora McKinsey, basada en la información suministrada por el Global Projects Database, IHS Herold (www.herold.com) muestra[2] que un conjunto significativo de grandes proyectos de construcción había tenido retrasos del 20% sobre la duración planificada y un sobrecoste muy significativo del 80% (Figura 2).
En ese mismo informe se señala que esa baja tasa de productividad se debe a varias razones, y en lo que atañe a este proyecto de I+D+i es relevante señalar que una de ellas es la ejecución de pobres e incompletas planificaciones a corto plazo.
————————————————
[1] FIEC (European Construction Industry Federación). http://www.fiec.eu/en/the-construction-industry/in-figures.aspx
[2]https://www.mckinsey.com/industries/capital-projects-and-infrastructure/our-insights/reinventing-construction-through-a-productivity-revolution
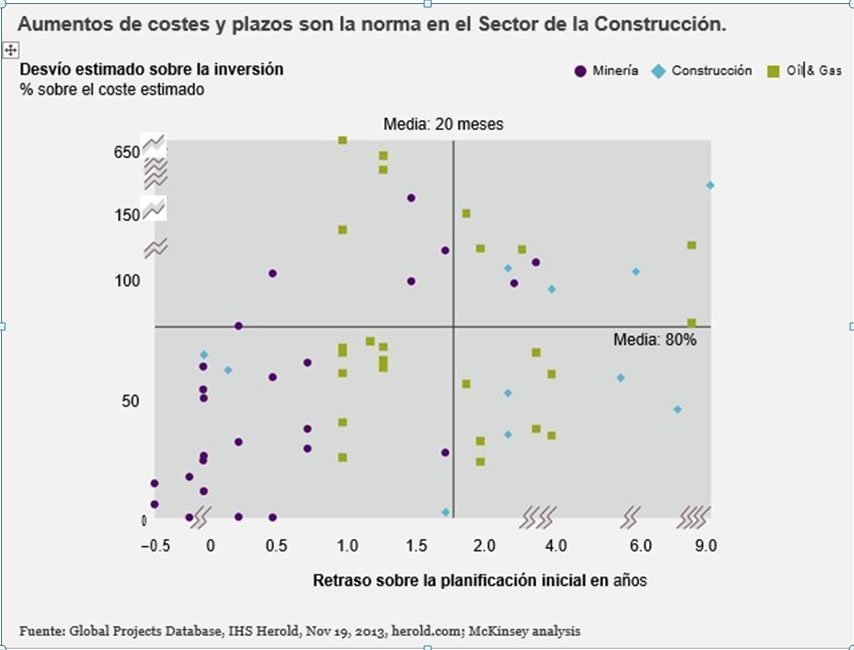 Figura 2: Aumentos de costes y plazos en las obras de construcción
Figura 2: Aumentos de costes y plazos en las obras de construcción
En ese mismo sentido, en otro reciente informe del McKinsey Global Institute publicado en febrero de 2017 y titulado “Reinventing Construction: A Route to Higher Productivity”, se indica que el factor más importe en términos de productividad es la eficiencia y la intensidad del uso de los recursos mano de obra y capital (Figura 3).
También señala que el sector adolece de una pobre gestión de los proyectos. Y, por ello, es muy importante disponer de un sistema de planificación y control de la producción de los proyectos de construcción que no se base en el plazo tradicional de control mensual.
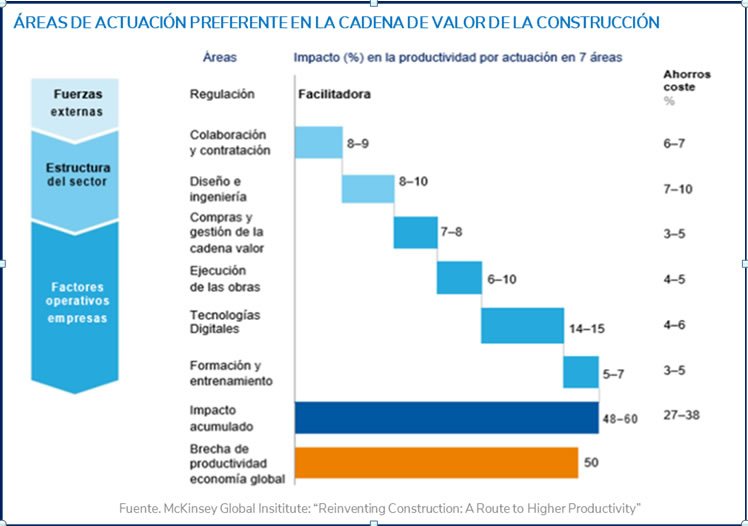 Figura 3: Áreas preferentes de actuación en las obras de construcción
Figura 3: Áreas preferentes de actuación en las obras de construcción
En ningún otro contexto como los proyectos de construcción es necesario planificar tantos frentes de forma simultánea y gestionar una significativa cantidad de información. Por ello, tecnologías como BIG Data Analytics, Inteligencia Artificial o BIM, entre otras, son fundamentales, y su uso será muy relevante y decisorio, en términos de competitividad y continuidad del negocio.
La industria de la Construcción adolece de una insuficiente innovación y, especialmente, de una pobre implantación de tecnologías informáticas de última generación que sirvan de soporte a la toma de decisiones, donde una de las más relevantes para las empresas constructoras es la que tiene que ver con decidir a qué licitaciones públicas o privadas se van a presentar. En esa toma de decisiones, el coste y plazo (y, de forma implícita, el riesgo) de la obra a licitar se constituyen como decisiones a tomar de máxima relevancia.
2. Big Data Analytics e Inteligencia Artificial (I): Definiciones y recorrido histórico
2.1. ¿Qué es Big Data?
La capacidad de procesar grandes cantidades de datos y de extraer información ha revolucionado la situación de nuestra sociedad. Este fenómeno, denominado como Big Data, tiene aplicaciones para una amplia gama de industrias, y, entre ellas, para nuestra industria de la construcción. La industria de la construcción genera grandes volúmenes de datos heterogéneos, que se espera aumenten exponencialmente a medida que tecnologías como las redes de sensores y el Internet de las cosas -entre otras – se vayan convertido en “commodities”, es decir, en bienes de consumo masivo indiferenciado.
BIG DATA es un término que hace referencia a una cantidad de datos tal que supera la capacidad del software tradicional para ser capturados, gestionados y procesados en un tiempo razonable y que requieren tecnologías avanzadas para su adecuado tratamiento, con el fin de extraer información de valor útil.
Esa extracción del valor que reside en los datos y que no es evidente, se puede poner de manifiesto mediante novedosos algoritmos y tecnologías de análisis y es lo que se denomina Big Data Analytics.
Así pues, Big Data se refiere al procedimiento de “recopilar ahora y organizar más tarde”, es decir capturar y almacenar datos de interacciones y transacciones diversas de forma continuada, para encontrar su significado y su utilidad, en un paso posterior.
En esa definición, se diferencian, por tanto, Big Data (recoger y almacenar datos masivos) del proceso de extraer valor de los datos, que a menudo se le llama Analytics.
Sus características se conocen popularmente como las «V» del Big Data, dado que comienzan por dicha letra del alfabeto. No hay un consenso sobre cuántas “V” han de ser tenidas en consideración y de hecho la lista se ha ido ampliando, pero se puede afirmar que las 7 «V» del Big

Data más extendidas son las que se recogen en la figura 4.
Figura 4: Las 7 v´s del Big Data.
Fuente: Facultad de Estudios Estadísticos. Universidad Complutense de Madrid
2.2. Tipos de datos en Big Data
Otras definiciones ponen de manifiesto a Big Data por el tipo de datos que incluye, como se puede ver en la figura siguiente:
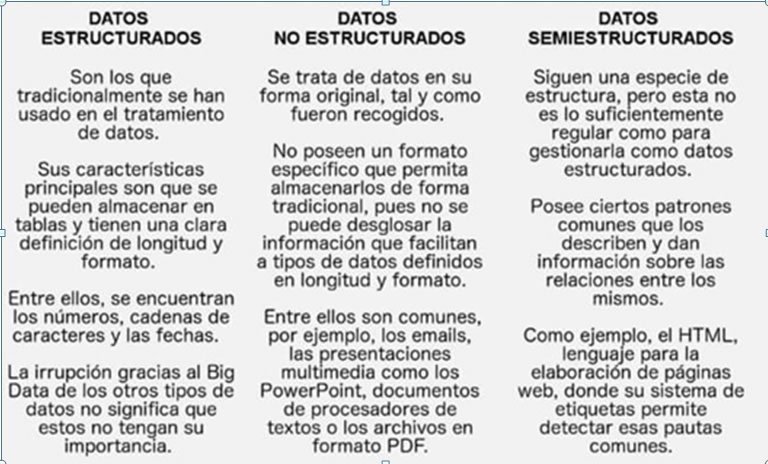 Figura 5: Tipos de datos en Big Data. (Fuente: Facultad de Estudios Estadísticos. Universidad Complutense de Madrid
Figura 5: Tipos de datos en Big Data. (Fuente: Facultad de Estudios Estadísticos. Universidad Complutense de Madrid
Conviene señalar las fuentes origen de los datos. Estas son las siguientes:
· Generados por personas: envíos de correos electrónicos, escribir un comentario en Facebook, contestar a una encuesta telefónica, introducir información en una hoja de cálculo, responder a un WhatsApp, coger los datos de contacto de un cliente, hacer clic en un enlace de Internet… Infinidad de acciones que realizamos en el día a día y que suponen una fuente de datos inmensa.
· Comunicación entre máquinas, sensores y dispositivos. Las cámaras de control de tráfico, los parquímetros o los sistemas de riego automático de las ciudades, los GPS de vehículos y teléfonos móviles, las máquinas expendedoras de bebidas y alimentos en un hospital, los sensores en túneles o los contadores inteligentes de electricidad de las viviendas, por poner unos pocos ejemplos, se comunican a través de dispositivos con otros aparatos, a los que transmiten los datos que van recogiendo. En definitiva, el Internet de las cosas (IoT) en el que los objetos inteligentes ofrecen millones de datos provenientes del aumento del número de dispositivos conectados entre sí, ya sea a través de Internet o microchips.
· Biométricas. Los datos que tienen como origen artefactos como sensores de huellas dactilares, escáneres de retina, lectores de ADN, sensores de reconocimiento facial o reconocimiento de voz. Su uso es muy extendido en materia de seguridad en todas sus variantes (privada, corporativa, militar, policíaca, de servicios de inteligencia, etcétera).
Marketing en la Web. Nuestros movimientos en Internet están sujetos a todo tipo de mediciones que tienen como objeto estudios de marketing y análisis de comportamiento. Por ejemplo, cuando se realizan mapas de calor basados en el rastreo del movimiento del cursor por parte de los usuarios de una web, en la detección de la posición de la página, o en el seguimiento de desplazamiento vertical a lo largo de esta. Con esos datos se llega a conclusiones tales como qué partes de una página atraen más al usuario, dónde hace clic o en qué zona de esta pasa más tiempo.
· Sistemas de transacciones de datos. El traspaso de dinero de una cuenta bancaria a otra, la reserva de un billete de avión o añadir un artículo a un carrito de compra virtual de un portal de comercio electrónico, serían algunos ejemplos concretos.
2.3. Big Data Analytics
Big Data Analytics es un método de trabajo y un conjunto de tecnologías para descubrir los patrones e interrelaciones ocultos en grandes volúmenes de datos y extraer información útil para su gestión y análisis. Y es, también, un proceso de inspección, diferenciación y transformación de esos inmensos volúmenes de datos con el objetivo de identificar esa información útil, sugerir conclusiones y ayudar a tomar las decisiones adecuadas para el negocio. Los análisis incluyen tanto la minería de datos como la comunicación o la toma de decisiones.
La mayoría de los datos en bruto no ofrecen demasiado valor si no se han procesado. Pero si se aplican las herramientas y técnicas adecuadas, se podrá extraer información valiosa. Por ello, independientemente del tipo de Big Data Analytics que se emplee, el primer paso siempre es capturar una gran cantidad de información.
2.3.1. Naturaleza multidisciplinar del Big Data Analytics
Big Data Analytics incorpora un largo recorrido científico e intelectual e incorpora subconjuntos de una amplia variedad de materias. Tradicionalmente ha habido muchas disciplinas relacionadas que tienen esencialmente el mismo enfoque central: encontrar patrones útiles en los datos (pero con un énfasis diferente cada una de ellas). Estos campos relacionados son Estadística, Bases de Datos, Minería de Datos, Análisis Predictivo, Analítica de Negocios, Descubrimiento de Conocimiento de Bases de Datos (KDD), Analítica de Datos, Neurociencia Computacional y, la más reciente, Big Data. La figura 6 muestra de forma resumida la relevancia y ubicación de estos campos multidisciplinarios para Big Data Analytics, que más adelante serán descritos.
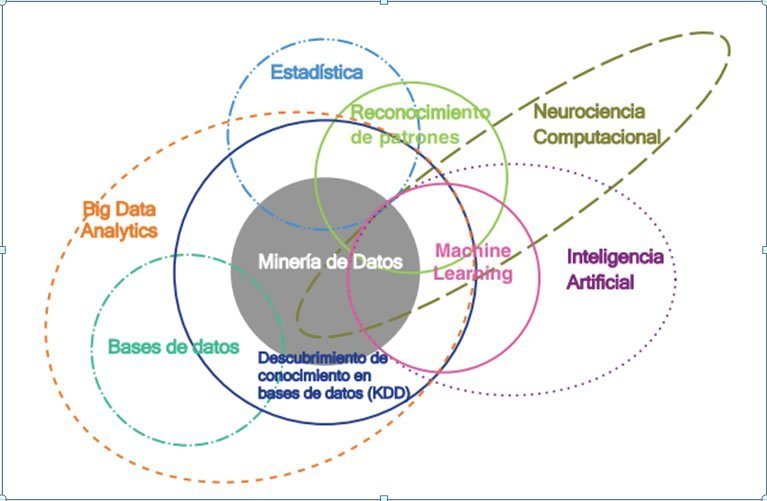
Por lo tanto, Big Data Analytics es una ampliación del campo de la analítica de datos e incorpora muchas de las técnicas que se han ido aplicando desde el nacimiento de la ciencia estadística en 1830, todas ellas destinadas, con diferentes énfasis y alcances, a encontrar información útil en los datos.
2.3.2. Descripción de las materias que integran Big Data Analytics
2.3.2.1. Estadística: los orígenes
Se puede definir la Estadística como la ciencia para la recolección, análisis, interpretación, presentación y organización de hechos numéricos (datos) con el objetivo principal de aprender de los mismos y extraer conclusiones. Desde su nacimiento se ha ido construyendo un conjunto de rigurosas y eficientes técnicas tendentes a dar respuestas a las preguntas formuladas en diversos ámbitos de actuación.
El termino estadística proviene del latín “statisticum collegium” (“Consejo de Estado”) y de su derivado italiano “statista” (“hombre de Estado o político”). En 1749, el profesor y matemático alemán Gottfried Achenwall comenzó a utilizar la palabra alemana “statistik” para designar el análisis de datos estatales. Por lo tanto, los orígenes de la estadística están relacionados con el gobierno y sus cuerpos administrativos. Curiosamente, Shakespeare ya utilizó la palabra «Estadística» en su drama Hamlet (1602). En el pasado, las estadísticas eran utilizadas por los gobernantes que designaban el análisis de datos sobre el estado, lo que significaba la «ciencia del estado».
En los siglos XVII y XVIII la obra de estudiosos como Gerolamo Cardano, Blaise Pascal, Jakob Bernoulli, Abraham de Moivre, Thomas Bayes y Richard Price sentó las bases de la teoría de la probabilidad y, a lo largo del siglo XIX, la teoría de la probabilidad se convirtió en una de las más importantes del mundo.
En ese siglo XIX, muchos estadísticos comenzaron a utilizar las distribuciones de probabilidad como parte de su conjunto de herramientas analíticas. Estos nuevos avances en matemáticas permitieron a los estadísticos ir más allá de las estadísticas descriptivas y comenzar a desarrollar el aprendizaje estadístico. Pierre Simon de Laplace y Carl Friedrich Gauss son dos de los matemáticos más importantes y famosos del siglo XIX, y ambos hicieron importantes contribuciones al aprendizaje estadístico y a la ciencia de datos moderna. Laplace tomó las intuiciones de Thomas Bayes y Richard Price y las incluyó en la primera versión de lo que ahora llamamos la Regla de Bayes. Gauss, en su búsqueda del planeta enano desaparecido Ceres, desarrolló el método de los mínimos cuadrados, que nos permite encontrar el mejor modelo que se ajusta a un conjunto de datos de tal manera que el error en el ajuste minimice la suma de las diferencias elevadas al cuadrado entre los puntos de datos en el conjunto de datos y el modelo. El método de mínimos cuadrados proporcionó la base para métodos de aprendizaje estadístico como la regresión lineal y la regresión logística, así como el desarrollo de modelos de redes neuronales artificiales en la inteligencia artificial tan en boga hoy en día.
 Figura 7. Thomas Bayes (izqda.) Pierre Simon de Laplace (centro) y Carl Friedrich Gauss (dcha.)
Figura 7. Thomas Bayes (izqda.) Pierre Simon de Laplace (centro) y Carl Friedrich Gauss (dcha.)
Entre 1780 y 1820, más o menos al mismo tiempo que Laplace y Gauss hacían sus contribuciones al aprendizaje estadístico, un ingeniero escocés llamado William Playfair inventaba los gráficos estadísticos y sentaba las bases para la visualización moderna de datos y el análisis exploratorio de datos. Playfair inventó el diagrama de líneas y el diagrama de área para datos de series temporales, el diagrama de barras para ilustrar comparaciones entre cantidades de diferentes categorías, y el diagrama de tartas para ilustrar proporciones dentro de un conjunto. La ventaja de visualizar datos cuantitativos es que nos permite usar nuestras habilidades visuales para resumir, comparar e interpretar datos. Es cierto que es difícil visualizar conjuntos de datos grandes (muchos puntos de datos) o complejos (muchos atributos), pero la visualización de datos sigue siendo una parte importante de la ciencia de datos. En particular, es útil para ayudar a los científicos a explorar y comprender los datos con los que trabajan. Las visualizaciones también pueden ser útiles para comunicar los resultados de un proyecto de investigación estadística. Desde la época de Playfair, la variedad de gráficos de visualización de datos ha crecido constantemente, y hoy en día se está investigando en el desarrollo de enfoques novedosos para visualizar grandes conjuntos de datos multidimensionales.

Antecedentes de la Inteligencia Artificial.
Alan Mathison Turing matemático, científico de la computación, criptógrafo y filósofo, es considerado uno de los padres de la ciencia de la computación y precursor de la informática moderna. Proporcionó una influyente y relevante formalización de los conceptos de algoritmo y computación.
Durante la segunda guerra mundial, trabajó en descifrar los códigos de comunicación nazis, particularmente los de la máquina Enigma. Se cree que su trabajo acortó la duración de esa guerra entre dos y cuatro años. Tras la guerra, diseñó uno de los primeros ordenadores electrónicos programables en el Laboratorio Nacional de Física del Reino Unido y poco tiempo después construyó el primer ordenador con almacenamiento de programas en memoria, la Manchester Mark 1 para la Universidad de Manchester, operativa en abril de 1949.
Los trabajos de Alan Turing en la Segunda Guerra Mundial que condujeron a la invención del ordenador electrónico, tuvieron un impacto dramático en la época porque permitía cálculos estadísticos mucho más complejos y a mucha más velocidad.


Warren McCulloch y Walter Pitts (1943) (figura 9) han sido reconocidos como los autores del primer trabajo en Inteligencia Artificial cuando presentan el primer modelo matemático de una red neuronal artificial. Partieron de tres fuentes: conocimientos sobre la fisiología básica y el funcionamiento de las neuronas en el cerebro, el análisis formal de la lógica proposicional de Russell y Whitehead y la teoría de la computación de Alan Turing. Propusieron un modelo constituido por neuronas artificiales, en el que cada una de ellas se caracterizaba por estar “activada” o “desactivada”; la “activación” se daba como respuesta a la estimulación producida por una cantidad suficiente de neuronas vecinas. El estado de una neurona se vería como equivalente, de hecho, a una situación específica con unos estímulos “adecuados”. Mostraron, por ejemplo, que cualquier función de computación podría calcularse mediante alguna red de neuronas interconectadas, y que los conectores lógicos (“Y”, “O”, “NO”, etc.) se podían implantar utilizando estructuras de red sencillas. McCulloch y Pitts también sugirieron que redes neuronales adecuadamente definidas podrían aprender. Doriald Hebh (1949) propuso y demostró una sencilla regla de actualización para modificar las intensidades de las conexiones entre neuronas. Esa regla, ahora llamada de aprendizaje Hehbiano o de Hebb, sigue vigente en la actualidad.
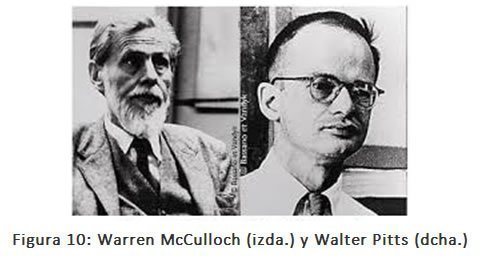



Auge inicial y grandes esperanzas (1956 – 1966)
Los primeros años de la Inteligencia Artificial estuvieron llenos de éxitos, aunque con ciertas limitaciones. Teniendo en cuenta lo primitivo de los ordenadores y las herramientas de programación de aquella época, y el hecho de que sólo unos pocos años antes, a los ordenadores se les consideraba como artefactos que podían realizar únicamente trabajos aritméticos y nada más, resultó sorprendente que un “computador” hiciese algo realmente inteligente. La comunidad científica, en su mayoría, prefirió creer que “… una maquina nunca podría hacer tareas”. Como es lógico, los investigadores de la Inteligencia Artificial de aquel entonces respondieron demostrando la ejecución de una tarea tras otra. John McCarthy se refiere a esa época como la era de “¡Mira mamá, ahora sin manos!”.
Un primer éxito fue la creación de un Sistema de Resolución General de Problemas (SRGP), diseñado para imitar protocolos de resolución de problemas tal y como lo hacían los seres humanos. Fue, posiblemente, el primer programa que incorporó el enfoque de “pensar como un ser humano”.


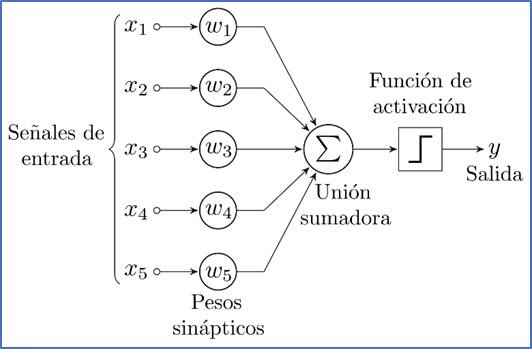
por Frank Rosenblatt con su Perceptron, la red neuronal artificial más simple.
Figura 12. Diagrama de un Perceptron con 5 señales de entrada


El primer invierno: una dosis de realidad (1966 – 1973)
Desde el primer momento, los investigadores de la IA hicieron públicas, sin el menor atisbo de timidez, predicciones sobre el éxito que se esperaba en esa prometedora disciplina. Así, hicieron pronósticos de que en 10 años un ordenador llegaría a ser campeón de ajedrez o que se podría demostrar un importante teorema matemático con una máquina. Esas y otras predicciones se cumplieron (al menos en gran parte) 40 años más tarde, pero no en diez. El exceso de confianza se debió a la prometedora actuación de los primeros sistemas de la IA en problemas simples. Así, en la mayor parte de los casos, resultó que esos primeros sistemas fallaron estrepitosamente cuando se intentaron emplear en problemas mas variados o de mayor dificultad.


Y el tercer obstáculo, posiblemente el detonante de este primer invierno de la IA, se derivó de las limitaciones inherentes a las estructuras básicas que es utilizaban en la generación de la conducta inteligente. La capacidad de los algoritmos de autoaprendizaje mediante retroalimentación aplicados era muy baja, si bien curiosamente ya en 1969, en la Standford University, Arthur Bryson, ingeniero aeronáutico norteamericano y Yo-Chi Ho, matemático chino-norteamericano habían sentado las bases del posterior resurgimiento de la investigación y uso de las redes neuronales a partir de finales de los 80, pero sus descubrimientos no fueron usados en aquella época. También fue muy influyente el libro publicado en 1969 por Minsky y Papert titulado “Perceptrons: An introduction to computational geometry” en el que criticaban una red neuronal diseñada por quien fuera un antiguo amigo de Minsky, Rosenblatt, dado que el Perceptron no era capaz de razonar o establecer planes, sino incluso de resolver funciones lógicas del tipo “XOR”, entre otros “defectos”. Ello significó un retraso de prácticamente década y media en el desarrollo de las Redes Neuronales Artificiales, hasta que los investigadores norteamericanos David Everett Rumelhart, y James Lloyd McClelland publicaron en 1986 el libro “Parallel distributed processing: Explorations in the microstructure of cognition”, que fue el detonante de un nuevo impulso en el campo de la ciencia cognitiva en general, y en las Redes Neuronales Artificiales, en particular, Impulso que continua hasta el presente.
Durante esta época, a pesar del pobre nivel tecnológico del software y hardware existente, se sentaron las bases de la Visión Artificial, fundamentalmente basados en los trabajos de Larry Roberts, ingeniero industrial norteamericano (MIT) nada menos que en 1961 y concretados en el reconocimiento visual de un universo formado por bloques en tres dimensiones: sólidos rectangulares, figuras piramidales, cuadradas y combinaciones de todas ellas. También se dio un notable impulso a la resolución automática de problemas y planificación, el procesamiento del lenguaje natural, el aprendizaje y programación automática, la representación del conocimiento y los sistemas expertos, así como la robótica. Y sentaron las bases para el desarrollo del siguiente período. Larry Roberts fue, además, quien concibió y puso en marcha la red ARPANET, antecesora de nuestra actual Internet.

Sistemas basados en el conocimiento: primer intento para resurgir la IA (1969 – 1980)
En esta década, la IA vivió una etapa con gran interés en el conocimiento, y es precisamente en esta etapa donde surgen la mayoría de propuestas de representación del conocimiento. Esto es consecuencia del auge inicial de los sistemas expertos (SE) y los sistemas basados en conocimiento (SBC). La mayoría de los sistemas de representación del conocimiento parten del hecho que el conocimiento se adquiere a partir de la experiencia, lo que implica que haya mucha similitud en cómo abordan el aprendizaje del mismo. Asimismo, en analogía con el ser humano, consideran la capacidad de generar nuevo conocimiento a partir del que ya posee, por lo que el método se basa en la inferencia a partir del conocimiento existente. Un factor esencial en los sistemas de representación es definir el ámbito y naturaleza del conocimiento que se pretende representar, para acotar el conocimiento general que es muy amplio.
Otra de las líneas de trabajo que se fueron desarrollando se centraron en la búsqueda heurística. Resumidamente, consiste en localizar la solución más idónea para un problema entre un abanico de soluciones disponibles. En muchas ocasiones, se desconoce cuál es la mejor solución posible. A veces se habla de solución “buena”, entendida como la mejor solución entre las encontradas y que satisface unos criterios de calidad básicos exigidos previamente. La palabra heurística proviene del griego “heurískein”, que significa “hallar”, “inventar”. Una búsqueda puede realizarse al azar o puede estar guiada mediante algún tipo de estrategia o procedimiento razonado. Es lo que en términos coloquiales sería “fuerza bruta” o establecer algunos criterios que permitan una búsqueda más inteligente. Un algoritmo de búsqueda heurística es un algoritmo computacional que ofrece un mecanismo para encontrar buenas soluciones ante un problema dado. No siempre garantiza que será capaz de encontrar la solución óptima al problema, o que será capaz de encontrar esa solución empleando un tiempo aceptable.
La resolución de problemas durante este período de investigación en la IA se centró en el desarrollo de mecanismos de búsqueda de propósito general, en los que se entremezclaban elementos básicos de razonamiento para encontrar soluciones completas. A estos procedimientos se les ha denominado “métodos débiles” debido a que no trataban problemas más amplios o complejos. Y la alternativa a los métodos débiles es el uso de conocimiento específico del dominio en el que se trabaja, es decir, que, para resolver un problema en la práctica, sería necesario saber de antemano la respuesta, y a partir de ella, generar conocimiento o aprendizaje en el sistema para evaluar soluciones, generalmente de casos recurrentes en ámbitos de conocimiento restringido para reducir el número de posibles soluciones.
El programa DENDRAL constituye uno de los primeros ejemplos de este enfoque. Fue diseñado por un grupo de investigadores de la Universidad de Stanford con el fin de encontrar la solución del problema de inferir una estructura molecular desconocida a partir de la información proporcionada por un espectrómetro de masas.
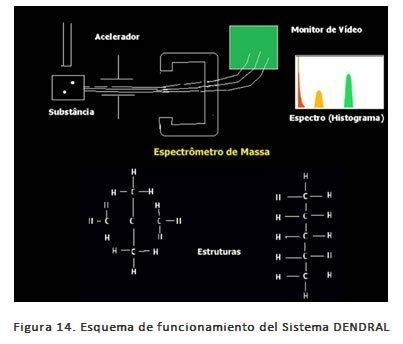
La versión más simple del programa generaba todas las posibles estructuras moleculares que correspondieran a la fórmula, luego predecía el espectro de masas que se observaría en cada caso, y comparaba éstos con el espectro real. Como era de esperar, el método anterior resultó rápidamente inviable para el caso de moléculas con un tamaño considerable. Pero supuso un hito y un éxito en su momento. En sistemas diseñados posteriormente se incorporó una gran mejora mediante una nítida separación del conocimiento (en forma de reglas) de la parte correspondiente al razonamiento.
El siguiente gran esfuerzo se realizó en el área del diagnóstico médico mediante la puesta en funcionamiento en 1974 del sistema MYCIN, destinado al diagnóstico de infecciones sanguíneas. Con 450 reglas aproximadamente, MYCIN era capaz de hacer diagnósticos tan buenos como los de un experto y, desde luego, mejores que los de un médico recién graduado. La novedad de este sistema consistió en que las reglas incluidas en el mismo se obtuvieron a partir de extensas entrevistas con los expertos, quienes las habían obtenido de libros de texto, de otros expertos o de su experiencia directa en casos prácticos. Y, en segundo lugar, las reglas deberían reflejar la incertidumbre inherente al conocimiento médico.
En geología se desarrollaron los sistemas PROSPECTOR (1974) y DIPMETER (1980). El primero, tenía como objetivo encontrar minerales, y en el caso de DIPMETER su objetivo era la búsqueda de yacimientos petrolíferos. Se pueden encontrar ejemplos de Sistemas Expertos en diferentes campos en este período de tiempo, como por ejemplo en defensa, en planificación de misiones, en entornos bancarios, en entidades financieras y, por supuesto, en medicina. En este último campo, cabe destacar ONCOCIN, que desde 1981 ha sido utilizado por la Facultad de Oncología de Stanford.
La IA se convierte en una industria (1980 – 1987)
Un sistema experto llamado R1 o XCON, abreviatura de “eXpert CONfigurer” (configurador experto), desarrollado por John McDermott, informático e investigador de la Carnegie-Mellon University en 1979, llegó a diseñar el 93% de las puertas lógicas del ordenador VAX 9000 del fabricante de ordenadores Digital Equipment Corporation (DEC). El sistema XCON, cuyo objetivo consistía en la elaboración de configuraciones y pedidos de sistemas informáticos, dispuso de 1.000 reglas escritas a mano. La tasa de errores debido al proceso realizado por expertos humanos fue de alrededor de 1 error por cada 200, mucho menor que la tasa de 1 error por cada 20,000 configuraciones que registró XCON.
En 1986, XCON representó para la compañía un ahorro estimado de 40 millones de dólares al año. En 1988, el grupo de Inteligencia Artificial de DEC había distribuido ya 40 sistemas expertos. La compañía Du Pont utilizaba ya 100 y estaban en etapa de desarrollo 500 más, lo que le generaba ahorro de diez millones de dólares anuales aproximadamente. Casi todas las compañías importantes de Estados Unidos contaban con su propio grupo de IA, en el que se utilizaban o investigaban sistemas expertos.
En 1981 los japoneses anunciaron el proyecto “Quinta Generación”, un plan de diez años para construir ordenadores inteligentes en los que pudiese ejecutarse el lenguaje de programación Prolog para el desarrollo de aplicaciones de IA. Como respuesta Estados Unidos constituyó la Microelectronics and Computer Technology Corporation (MCC), consorcio encargado de mantener la competitividad nacional en estas áreas. En ambos casos, la IA formaba parte de un gran proyecto que incluía el diseño de chips y la investigación de la relación hombre máquina. Sin embargo, los componentes de IA generados en el marco de MCC y del proyecto Quinta Generación nunca alcanzaron sus objetivos. La respuesta de la Europa continental fue el lanzamiento del programa ESPRIT (European Strategic Programme for Research in Information Technology – Programa Estratégico Europeo en Investigación de la Tecnología de la Información) en 1984.
En el Reino Unido, el informe Alvey (1982) restauró el patrocinio suspendido por el informe Lighthill publicado en 1973, y recomendó al gobierno británico la financiación durante 10 años del desarrollo de inteligencia artificial para sistemas inteligentes basados en el conocimiento, entre otras tecnologías.
También en 1981, la General Electric Company se encontró con el problema de que su mejor ingeniero, David Smith, deseaba jubilarse. La solución adoptada fue aplicarle a Smith las técnicas de ingeniería del conocimiento y codificar sus habilidades intelectuales en un sistema experto. La General Electric no sólo consiguió el objetivo prioritario de seguir disponiendo del talento de Smith después de que éste se jubilase, sino que además lo multiplicó en copias que se distribuyeron por las oficinas de la compañía a lo largo de los Estados Unidos. Fue lo mismo que hizo la Campbell’s Soup Company con su especialista en hidrostática, Aldo Cimino, o la General Motors con su ingeniero Charlie Amble. Copias en discos de la única parte de la mente de los seres humanos que interesa al capital, guiado por la razón instrumental: la productividad y la eficiencia.
La industria militar no iba a la zaga, y las inversiones públicas a través de DARPA regresaron en forma de proyectos como, por ejemplo, el de un camión militar conducido por un piloto automático.
El segundo invierno de la IA (1987 – 1993)
La adopción de los sistemas expertos por parte de corporaciones de todo el mundo y la reanudación de las inversiones desde el comienzo de los 80 por los gobiernos de Japón, los Estados Unidos o el Reino Unido, entre otros, sirvieron para popularizar un nuevo método de entrenamiento para redes neuronales, con el algoritmo “backpropagation”, la comercialización con éxito de nuevas aplicaciones para OCR (Reconocimiento Óptico de Caracteres) y el reconocimiento de voz basados en aquellas tecnologías.
Sin embargo, hacia finales de los 80 y principios de los 90, el mundo de la IA sufrió una serie de episodios turbulentos. El primero fue el colapso repentino del mercado de hardware especializado en Inteligencia Artificial en 1987. Las computadoras de escritorio de IBM y Apple habían mejorado en velocidad y potencia, y en ese año, superaron a las computadoras especializadas y caras. Ya no había razón para comprarlas, y toda una industria desapareció de la noche a la mañana.
El segundo motivo, conceptual y/o científico fue que, de la impresionante lista de objetivos establecidos para la IA a principios de la década, la mayoría permanecía sin resolver, y ello a pesar del notable aumento de potencia y almacenamiento de los sistemas informáticos respecto de la década anterior. Los antecedentes se pueden encontrar en 1984 como tema de un debate público en la reunión anual de la AAAI (entonces llamada «American Association of Artificial Intelligence»).
En dicha reunión, los expertos investigadores Roger Schank, informático y psicólogo cognitivo por la Universidad de Texas, y Marvin Minsky, matemático por Harvard, ambos norteamericanos, advirtieron de que el entusiasmo por la nueva tecnología estaba fuera de control.


El efecto más importante de los ordenadores personales sobre la IA fue más de tipo psicológico que económico. Las máquinas como el Macintosh de Apple no se comercializaban como «cerebros electrónicos» con el propósito de sustituir a la inteligencia humana, sino para servir de apoyo a ésta poniendo a su disposición herramientas como hojas de cálculo, procesadores de texto y programas de diseño gráfico. Esta nueva visión de las computadoras se trasladó a los sistemas expertos. Así, mientras que en los 80 el objetivo era convertirlos en sustitutos de seres humanos, en los 90 pasaron a ser simples consultores o herramientas de ayuda.
El regreso de las redes neuronales: la IA se convierte en una ciencia (desde 1986 hasta 2006)
En el ámbito de la inteligencia artificial existen dos aproximaciones: la Inteligencia Artificial simbólico-deductiva y la Inteligencia Artificial subsimbólica-inductiva. La diferencia entre las dos es la forma como se formaliza el conocimiento. Las técnicas simbólicas representan el conocimiento mediante símbolos, mientras que la IA subsimbólica busca conseguir un comportamiento inteligente sin necesidad de explicitar el conocimiento adquirido. Así, por ejemplo, ante el problema de saber encontrar al famoso personaje Wally en una imagen, los métodos simbólicos empezarían para describir cómo es Wally, mientras que los métodos subsimbólicos partirían de imágenes de ejemplo.
Cada una de las aproximaciones o paradigmas de la IA tiene sus ventajas e inconvenientes. Por ejemplo, con las técnicas de IA simbólica (reglas, ontologías, algoritmos de busca e inferencia) es más sencillo controlar el proceso de toma de decisiones, explicar el resultado y depurar el proceso en caso de errores. En cambio, con técnicas subsimbólicas (como por ejemplo las redes neuronales) no se necesita disponer de tanto conocimiento a priori, el rendimiento que se puede conseguir es más alto y se pueden escalar fácilmente añadiendo más recursos.
Precisamente, estas ventajas y su efectividad en problemas reales han hecho que las técnicas subsimbólicas sean el paradigma dominante en la actualidad. En este sentido, uno de los términos de mayor actualidad es el Deep Learning, cuya paternidad podemos asignar en gran parte a Geoffrey Hinton, psicólogo e informático anglo-canadiense (Universidad de Edimburgo), una rama del aprendizaje computacional que se utiliza en proyectos cómo Google Brain.
 A mediados de los 80, la moderación de las expectativas puestas en los sistemas expertos contribuyó al resurgir de las redes neuronales artificiales. Tras más de una década abandonadas por culpa de las duras críticas de Minsky contra el perceptrón de Rosenblatt, el programa de investigación de la IA subsimbólica regresó al centro de la escena gracias a dos acontecimientos. El primero fue la publicación de un artículo en 1982 en el que el físico John Hopfield (Cornell University) describía unas redes de neuronas autoasociativas de cuya interacción emergían habilidades computacionales. El segundo, aún más importante, y citado anteriormente, fue la edición en 1986 de dos volúmenes titulados “Parallel distributed processing” (Procesamiento distribuido en paralelo), o simplemente PDP, obra de un grupo de investigadores conocidos como Grupo PDP bajo la dirección de los psicólogos David Rumelhart de la Universidad de San Diego y James McClelland de la Universidad Carnegie-Mellon. El PDP, siglas sinónimas en la actualidad del enfoque subsimbólico o conexionista, consiguió pronto éxitos muy notables que llamaron la atención de la comunidad científica.
A mediados de los 80, la moderación de las expectativas puestas en los sistemas expertos contribuyó al resurgir de las redes neuronales artificiales. Tras más de una década abandonadas por culpa de las duras críticas de Minsky contra el perceptrón de Rosenblatt, el programa de investigación de la IA subsimbólica regresó al centro de la escena gracias a dos acontecimientos. El primero fue la publicación de un artículo en 1982 en el que el físico John Hopfield (Cornell University) describía unas redes de neuronas autoasociativas de cuya interacción emergían habilidades computacionales. El segundo, aún más importante, y citado anteriormente, fue la edición en 1986 de dos volúmenes titulados “Parallel distributed processing” (Procesamiento distribuido en paralelo), o simplemente PDP, obra de un grupo de investigadores conocidos como Grupo PDP bajo la dirección de los psicólogos David Rumelhart de la Universidad de San Diego y James McClelland de la Universidad Carnegie-Mellon. El PDP, siglas sinónimas en la actualidad del enfoque subsimbólico o conexionista, consiguió pronto éxitos muy notables que llamaron la atención de la comunidad científica. 

La importancia de este proceso consiste en que, a medida que se entrena la red, las neuronas de las capas
intermedias se organizan a sí mismas de tal modo que estas neuronas aprenden a reconocer distintas características del espacio de datos de entrada. Después del entrenamiento, cuando se les presente un patrón arbitrario de entrada que contenga ruido o que esté incompleto, las neuronas de la capa oculta de la red responderán con una salida activa si la nueva entrada contiene un patrón que se asemeje a aquella característica que las neuronas individuales hayan aprendido a reconocer durante su entrenamiento.
En 1989 Yann LeCun, científico francés experto en informática y máximo responsable de IA en Facebook, idea y desarrolla las redes neuronales convolucionales (CNN, por sus siglas en inglés), que son redes neuronales multicapa que toman su inspiración del córtex visual de los animales. Esta arquitectura es útil en varias aplicaciones, principalmente en el procesamiento de imágenes.
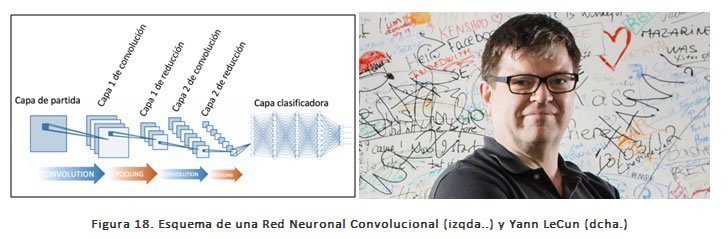
Las redes neuronales convolucionales trabajan modelando de forma consecutiva pequeñas piezas de información, y luego combinando esta información en las capas más profundas de la red. Una manera de entenderlas es que la primera capa intentará detectar los bordes y establecer patrones de detección de bordes. Luego, las capas posteriores trataran de combinarlos en formas más simples y, finalmente, en patrones de las diferentes posiciones de los objetos, iluminación, escalas, etc. Las capas finales intentarán hacer coincidir una imagen de entrada con todos los patrones y llegar a una predicción final como una suma ponderada de 
todos ellos. De esta forma las redes neuronales convolucionales son capaces de modelar complejas variaciones y comportamientos dando predicciones bastantes precisas.
Ya durante la década de los 90 se realizaron importantes avances, donde destaca la introducción de las redes neuronales de memoria de largo y corto plazo (LTSM, en inglés) por parte de Sepp Hochreiter, director del Institute for Machine Learning de la Johannes Kepler University (Linz, Austria) y Jürgen Schimdhuber, director científico del Dalle Molle Institute for Artificial Intelligence Research (Manno, Suiza). Las redes neuronales LTSM pertenecen a la categoría de las redes denominadas recurrentes, es decir, que no tienen una estructura de capas definida, sino que permiten conexiones arbitrarias entre las neuronas, incluso pudiendo crear ciclos; con esto se consigue crear la temporalidad, permitiendo que la red tenga memoria. Las redes neuronales recurrentes son muy potentes para todo lo que tiene que ver con el análisis de secuencias, como puede ser el análisis y traducción de textos, sonido o video, o para series temporales, como para predicciones de consumo eléctrico, valores en Bolsa, etc. Y singularmente, están incluidas en nuestros teléfonos inteligentes para el reconocimiento de la voz (Siri), transcribirla a texto o para la gestión de peticiones en aquellos dispositivos.

Estas redes profundas aportaron impresionantes resultados en algunas tareas, como la histórica derrota del ajedrecista Gary Kaspárov ante el sistema Deep Blue de IBM en 1999.
Poco después de los logros de IBM con Deep Blue, se publicó uno de los conjuntos de datos más famosos, el conjunto de datos del Instituto Nacional de Estándares y Tecnología Modificado o el conjunto de datos MNIST (por sus siglas en inglés). El conjunto de datos MNIST es una colección de decenas de miles de dígitos escritos a mano, compilados por estudiantes de secundaria y empleados de la Oficina del Censo de los Estados Unidos.

Este conjunto de datos no solo se destaca como uno de los más utilizados para capacitar sistemas de procesamiento de imágenes y se utiliza en la comunidad de aprendizaje automático para el entrenamiento y evaluación de algoritmos de reconocimiento de imágenes. Además, ha sido la fuente de muchos sistemas de IA en línea mediante la cual los investigadores intentan generar la mejor precisión posible al reconocer dígitos en los diversos sistemas de procesamiento de imágenes que prueban.
Finalmente cabe mencionar que, al terminar esta etapa, se creía que las arquitecturas de redes profundas eran demasiado difíciles de entrenar y, por ello, tenían un futuro muy limitado. Sin embargo, sabemos ahora que estas arquitecturas aportan resultados realmente muy satisfactorios, pero eran demasiado costosas en términos de procesamiento informático para el hardware de la época y hubo que espera a la siguiente etapa para descubrirlo.
El aprendizaje profundo (Deep learning) (2006 hasta la actualidad).
La tercera era de las Redes Neuronales Artificiales comienza en 2006 debido a Geoffry Hinton, quien desarrolló una forma más eficiente de entrenar a las capas individuales de neuronas. La primera capa aprende características primitivas, como un borde en una imagen o la unidad más pequeña de sonido del habla, por ejemplo. Lo hace buscando combinaciones de píxeles digitales u ondas de sonido que se produzcan con más frecuencia de lo que deberían por casualidad. Una vez que esa capa reconoce con precisión esas características, son enviadas a la capa siguiente, que se entrena a sí misma para reconocer características más complejas, como una esquina o una combinación de sonidos del habla. El proceso se repite en capas sucesivas hasta que el sistema puede reconocer con seguridad fonemas u objetos.
Este avance permitió entrenar arquitecturas mucho más profundas que las utilizadas hasta el momento y, por ello, se popularizó el término “Deep Learning” o aprendizaje profundo. A partir de entonces, las RNAs empezaron a aportar resultados muy superiores a los obtenidos con otras técnicas de aprendizaje automático y se han ido convirtiendo en una de las ramas más destacadas de la IA.

El automóvil autónomo de Google (Waymo) se lanza en 2009, utilizando modelos de redes neuronales para interpretar y dar sentido a imágenes tridimensionales de entornos y condiciones de manejo. 
En 2011 se presenta Siri, una aplicación con funciones de asistente personal y con personalidad propia para el sistema operativo iOS de los móviles y tabletas de Apple. Esta aplicación utiliza procesamiento de lenguaje natural para responder preguntas, hacer recomendaciones y realizar acciones mediante la delegación de solicitudes hacia un conjunto de servicios web que ha ido aumentando con el tiempo. Esta aplicación es capaz de adaptarse con el paso del tiempo a las preferencias individuales de cada usuario, personalizando las búsquedas web y la realización de algunas tareas, tales como reservar mesa en un restaurante o pedir un taxi.
También en ese mismo año, 2011, Watson (https://www.ibm.com/watson), el sistema de IA paradigma de IBM demuestra sus capacidades antes los dos campeones más grandes del concurso de televisión estadounidense Jeopardy, y los vence. Watson es un sistema informático que se ejecuta en superordenadores IBM y que combina la inteligencia artificial (IA) y un sofisticado software analítico para un rendimiento óptimo como una máquina de «respuesta a preguntas». El superordenador lleva el nombre del fundador de IBM, Thomas J. Watson.
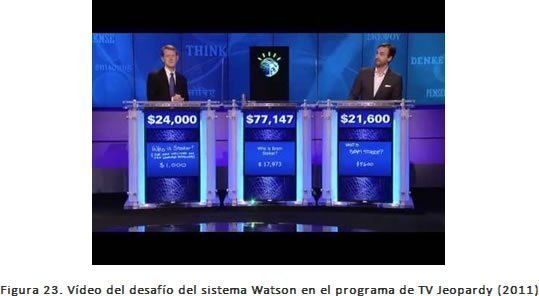
IBM asegura que su objetivo principal es crear un ordenador capaz de entender las preguntas que los humanos le hacen de una forma natural, y a la vez proveer la respuesta de una forma que los humanos puedan comprender. Para ello ha firmado un acuerdo con Nuance Communication para desarrollar un proyecto comercial que utilice en plenitud las habilidades de Watson.
En un artículo publicado en 2012 por Hinton y dos de sus estudiantes de Toronto, demuestran que las redes neuronales profundas, entrenadas con retropropagación, superaban a los sistemas más avanzados de reconocimiento de imágenes. Y el «aprendizaje profundo” comienza su despegue. Para el mundo exterior, la IA parecía despertar de la noche a la mañana.
En 2014 surgen las Redes Neuronales Generativas Adversarias (Generative Adversarial Networks, GAN como acrónimo). La idea detrás de GAN es la de tener dos modelos de redes neuronales compitiendo. Uno, llamado Generador, toma inicialmente “datos basura” como entrada y genera muestras. El otro modelo, llamado Discriminador, recibe a la vez muestras del Generador y del conjunto de entrenamiento (real) y deberá ser capaz de diferenciar entre las dos fuentes. Estas dos redes juegan una partida continua donde el Generador aprende a producir muestras más realistas y el Discriminador aprende a distinguir entre datos reales y muestras artificiales. Estas redes son entrenadas simultáneamente para finalmente lograr que los datos generados no puedan detectarse de datos reales.
Sus aplicaciones principales son la de generación de imágenes realistas, pero también la de mejorar imágenes ya existentes, o generar textos (captions) en imágenes, o generar textos siguiendo un estilo determinado y hasta el desarrollo de moléculas para industria farmacéutica, entre otras aplicaciones.
Siguiendo los pasos de MNIST vinieron los esfuerzos de Facebook en el procesamiento de imágenes. El lanzamiento de Facebook de su sistema de verificación facial DeepFace en 2014, mejoró significativamente las capacidades de programación de visión artificial por ordenador.

DeepFace tiene una precisión del 97,35% en el reconocimiento de rostros humanos, que se considera una tasa increíblemente alta de precisión en el campo. La razón por la que logró una tasa de precisión tan alta se debe en parte al acceso obvio y masivo de Facebook a las imágenes de los rostros de las personas en función de las imágenes cargadas en la plataforma de redes sociales.
Con el fin de probar las capacidades de DeepFace, el equipo de Facebook entrenó el Modelo de Red Neuronal Profunda de 9 capas en un conjunto de datos de 4 millones de imágenes faciales pertenecientes a 4.000 personas. El modelo contenía más de 120 millones de referencias utilizando varias capas conectadas localmente, en lugar de capas convolucionales estándar.
Antes de DeepFace, el sistema de identificación de próxima generación del FBI se consideraba el más preciso en el campo con una tasa de precisión del 85%. El algoritmo original de DeepFace se adquirió en realidad mediante la compra por Facebook de Face.com en 2007. Debido a la alta tasa de precisión obtenida a través del modelo DeepFace, el problema del reconocimiento de rostros se ha considerado esencialmente resuelto.
Google DeepMind fue noticia en 2016 cuando su interfaz AlphaGo venció a un jugador Go profesional por primera vez en la historia. Con base en las técnicas de aprendizaje de refuerzo, los diversos programas de DeepMind buscan «resolver la inteligencia» e implementar algoritmos que fomenten la comprensión a través de la experiencia.


2.4. Pero ¿qué es la IA?
En el fondo, lo que hemos viendo son diversos ámbitos de aplicación la IA y deberíamos haber empezado definiéndola. Sin embargo, antes de proceder a definir que es la IA, sería muy útil -y este es un problema muy arduo- llegar a entender que es la inteligencia humana, porque nos dará pistas muy interesantes, sobre la distancia que las separa a ambas.
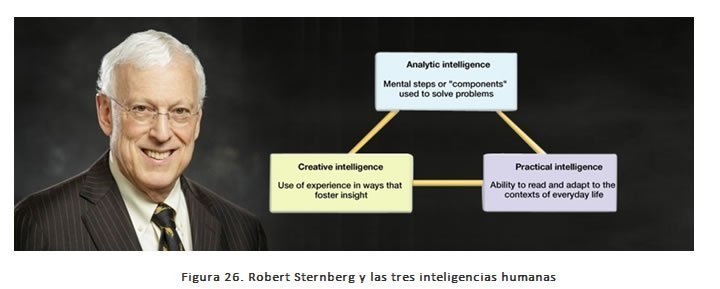
Para ese objetivo nos basaremos en lo que en esta materia Robert Sternberg, psicólogo de la Universidad de Yale, propone y es una de las teorías de la inteligencia más aceptadas de la actualidad. Su mérito consiste en que con ella consigue aunar la psicología evolucionista y la cognitiva sin dejar de lado aspectos volitivos, emocionales o relacionados con la creatividad. Sternberg define la inteligencia como la actividad mental que sirve para adaptar o conformar entornos relevantes para nuestra vida personal.
Según Sternberg hay tres tipos de inteligencia estrechamente interrelacionadas:
- Inteligencia analítica: dirección consciente de nuestros procesos mentales para analizar y evaluar ideas, resolver problemas y tomar decisiones. Es el tipo de inteligencia clásica que analizan los test.
- Inteligencia creativa: capacidad de afrontar tareas novedosas, formular nuevas ideas y combinar experiencias.
- Inteligencia práctica o contextual: capacidad de adaptación, selección o modificación del ambiente individual. Realmente, esta es la inteligencia más importante (si bien depende de las otras dos), ya que el éxito o fracaso vital de cada ser humano, dependerá de ella.
[13] https://medium.com/intuitionmachine/neurons-are-more-complex-than-what-we-have-imagined-b3dd00a1dcd3.
Curiosamente, los logros en el ámbito de la inteligencia artificial han hecho que su definición sea especialmente confusa, sobre todo porque uno podría preguntarse por ejemplo si DeepBlue podría considerarse inteligente cuando ganó a Kasparov al ajedrez, o si AlphaGo lo era cuando demostró ser mejor que cualquier humano jugando al Go. Sin duda que fueron grandes logros, pero son muy distintos de los que se están buscando en el campo de la IA. Por ello, a continuación, y basándonos en su teoría, vamos a repasar brevemente que tipos de inteligencia artificial existen en la actualidad.
La primera es la Inteligencia Artificial débil. Los sistemas de IA débil son capaces de resolver problemas muy bien definidos y acotados y han sido el detonante de la verdadera explosión de esta disciplina en los últimos tiempos. Así, se han aplicado distintas técnicas como aprendizaje máquina o aprendizaje profundo para lograr resolver problemas específicos, y los resultados han sido espectaculares.
Los logros alcanzados con Deep Blue o con AlphaGo son un paradigma perfecto de inteligencia artificial débil: estos sistemas se dedican a resolver un problema concreto y delimitado y los resuelven mucho mejor que un ser humano.
Estamos rodeados de inteligencias artificiales débiles (p. ej. los asistentes Alexa, Google Assistant, Siri y Cortana, los electrodomésticos inteligentes o los coches autónomos, entre otros muchos ejemplos), y de hecho estos son los desarrollos informáticos que más popularidad han logrado en los últimos tiempos porque han demostrado cómo es posible programar una máquina y entrenarla para resolver todo tipo de tareas. Lo hacen bien, pero no son capaces de adaptarse a su entorno (no tienen inteligencia práctica, según Sternberg). Así Cortana no podrá jugar al ajedrez con nosotros porque no está programada para ello, aunque podría ser posible adaptarla para esa tarea.
La segunda es la Inteligencia Artificial General. Es mucho más ambiciosa que la inteligencia artificial débil dado que podría resolver cualquier tarea intelectual resoluble por un ser humano. Esta inteligencia artificial sería multitarea y podría hacer cientos, miles de cosas distintas bien.
Pero no solo eso: esa inteligencia artificial general no sería una especie de gran unión de inteligencias artificiales débiles, cada una preparada para resolver un problema, sino que dicha inteligencia artificial general sería capaz de realizar juicios y razonar ante una situación de incertidumbre —a partir del aprendizaje y el entrenamiento—, además de comunicarse en lenguaje natural, planificar o aprender.
Y finalmente, la tercera. La Inteligencia Artificial Fuerte. La idea de una IA fuerte ha sido el sueño de casi todos los investigadores de ese campo. Sostiene que todas las operaciones mentales son manifestaciones sofisticadas de complicados procesos computacionales, y que es irrelevante si tales procesos son llevados a cabo por un sujeto humano, un objeto físico o un dispositivo electrónico. Por ello, acepta que la mente humana puede ser reproducida o copiada para otro medio, el cerebro se considera un soporte más.
La IA fuerte asume que la mente está formada por algoritmos altamente complejos que pueden ser descifrados y convertidos en programas de computadora, y de se llega a la conclusión que la mente humana puede ser digitalizada en un ordenador.
Este tipo de IA poseería los llamados “estados mentales” y, además, sería consciente de sí misma. Dicho tipo de inteligencia artificial iría más allá de emular, imitar y superar a los seres humanos en la realización de cualquier tarea. Al tomar consciencia de sí misma, sería capaz -teóricamente-de resolver cualquier problema y podría contar con una experiencia subjetiva propia, o ser capaz de sentir emociones. Y podría ser capaz de modificar el entorno a su conveniencia. Es decir, que sería inteligencia verdadera según la definición de Sternberg. Y entraríamos en un terreno escabroso en el que sería necesario hablar de los desafíos éticos que la aparición de dicha inteligencia artificial plantearía.
En esencia, una inteligencia artificial fuerte lograría contar con los estados mentales con los que contamos los seres humanos, pero lograría ir mucho más allá gracias a su capacidad de cálculo y de adaptación al entorno. Y tendríamos que ser cautos, porque que una inteligencia artificial fuerte es también general, pero lo contrario no es cierto. La diferencia es sutil, pero esa consciencia de sí misma probablemente lo cambiaría todo.
Si lográramos desarrollar esa inteligencia artificial fuerte, habríamos alcanzado ese punto de inflexión en la historia del ser humano. Uno en el que los problemas técnico-científicos, sociales o económicos no serían un reto para esa superinteligencia artificial. Habríamos alcanzado la singularidad y eso plantearía cambios impredecibles para nuestro mundo. Según los expertos en la materia, afortunada o desafortunadamente, parece que esta IA tardará aún mucho en llegar … si es que llega finalmente.
2.5. Áreas de aplicación de la Inteligencia Artificial ⌈14⌉
De la misma manera que a comienzos de la década de los 80 nadie se podía imaginar los grandes cambios que implicaría la irrupción del ordenador personal en nuestras vidas, no muchas personas son capaces hoy en día de imaginar en lo que se convertirá la IA en las próximas décadas. Sin embargo, parece que la IA emerge ya como un elemento clave en cualquier negocio que facilitará a aquellos que la implanten ir un paso por delante en su estrategia empresarial en términos de mejora de la experiencia de cliente, conocimiento del mercado y optimización de procesos y recursos.
A pesar de que la mayoría de los negocios no tienen implantados sistemas de IA avanzados o se encuentran en fases de desarrollo poco maduras, la IA es percibida por prácticamente la totalidad de los estamentos directivos de las compañías como una herramienta fundamental para obtener una ventaja competitiva respecto a los competidores. De hecho, el número de
[14] Informe “Bots, Machine Learning, Servicios Cognitivos. Realidad y perspectivas de la Inteligencia Artificial en España, 2018”. PwC

En los próximos años se prevé que, gracias al desarrollo de nuevos algoritmos, emergerán modelos de negocio disruptivos que forzarán a las empresas a comprender que la trasformación digital no es tan solo una tendencia, sino que es esencial para seguir manteniendo la competitividad, o, dicho de otra manera, asegurar la continuidad del negocio.
Algunas de las ventajas competitivas que aporta la IA son las siguientes:
- Optimización del tiempo y recursos a través de la automatización de procesos y tareas rutinarios.
- Reducción de costes a largo plazo.
- Incremento de la productividad y de la eficiencia operativa.
- Mejora en la toma de decisiones, incrementando la rapidez y la eficacia.
- Creación de nuevas líneas u oportunidades de negocio.
- Mejora de la satisfacción del cliente mediante la obtención de distintas perspectivas para predecir sus preferencias y ofrecerle una mejor y más personalizada experiencia.
- Aplicación de habilidades humanas mediante sistemas de conocimiento automatizados.
La inteligencia artificial, debido a su naturaleza, cuenta con diversas áreas de estudio, en las que se puede dividir y donde actualmente se está investigando. Cada una de las áreas de aplicación ha surgido gracias a ideas innovadoras en el ámbito de la investigación en el ámbito informático y científico donde distintas necesidades que día a día siguen surgiendo han facilitado el desarrollo de nuevas técnicas de programación y desarrollo de algoritmos.


De forma no exhaustiva, la aplicación de las tecnologías de IA en los sectores económicos se puede ver en el siguiente cuadro:
Medicina y Salud  |
|
Construcción |
|
Ingeniería Industrial y robótica  |
|
Ingeniería de software |
|
Educación |
|
Entretenimiento |
|
Biología |
|
Legal |
|
Aeroespacial |
|
Defensa |
|
Para los lectores que quieran un análisis más detallado de las áreas de la IA se dispone del siguiente enlace, una página web en inglés con muchos contenidos -especialmente mapas tecnológicos y posicionamiento de empresas proveedoras- y enlaces a diversos informes de consultoras:
https://emerj.com/ai-sector-overviews/artificial-intelligence-industry-an-overview-by-segment/
Información del mismo tipo, así como mapas de posicionamiento y tendencias tecnológicas en IA se puede encontrar en las páginas de firmas consultoras internacionales tales como:
- McKinsey & Company (https://www.mckinsey.com/featured-insights/artificial-intelligence)
- Forrester (https://www.forrester.com/Artificial-Intelligence-%28AI%29#)
- Gartner (https://blogs.gartner.com/smarterwithgartner?s=artificial+intelligence)
- Accenture (https://www.accenture.com/us-en/insights/artificial-intelligence-index)
- PwC (https://www.pwc.com/gx/en/issues/data-and-analytics/publications/artificial-intelligence-study.html)
- Deloitte (https://www2.deloitte.com/insights/us/en/tags/artificial-intelligence.html)
- KPMG (https://home.kpmg/xx/en/home/insights/2018/03/recognizing-the-value-of-artificial-intelligence.html)
- Grant Thornton (https://www.grantthornton.com/library/articles/advisory/2019/AI-machine-learning-and-analytics.aspx)
- Cap Gemini (https://www.capgemini.com/hot-topic/artificial-intelligence/)
Como ejemplo, un reciente informe de la consultora PwC (op. cit. nota 14) señala las tecnologías con mayor aplicación en España:
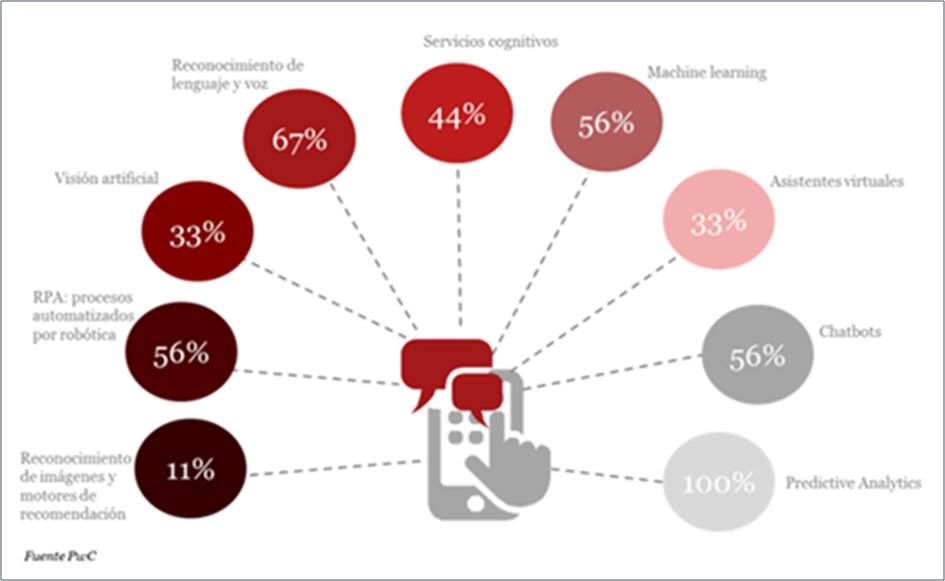
Figura 27. Tecnologías de IA en las que se prevé mayor aplicación en España
Finalmente, conviene citar que, en la 3ª parte de este documento, se llevará a cabo un análisis mas detallado de las aplicaciones de estas tecnologías en el sector de la Ingeniería y la Construcción.
2.5. Referencias
- The Quest for Artificial Intelligence. A History of Ideas and Achievements. Nils J. Nilsson. Standford University (2010).
- Inteligencia artificial. Un enfoque moderno (2ª edición). Stuart Russell y Peter Norvig. Pearson Prentice Hall (2008).
- Introduction to Artificial Intelligence (Second edition). Wolfgang Ertel. Springer (2017).
- La Inteligencia Artificial aplicada a la Defensa. Instituto Español de Estudios Estratégicos y Centro Superior de Estudios de la Defensa Nacional (CESEDEN) (2018).
- Data Science in Practice. Alan Said y Vicenç Torra. Springer (2019).
- Mastering Machine Learning with Python in Six Steps. Manohar Swamynathan. Appres (2017).
- Artificial Intelligence. What Everyone Needs to Know. Jerry Kaplan. Oxford University Press. 2016.
{kind=link}